Ruby で Double-Array を実装して Common-Prefix Search を試してみる
Double-Array (ダブル配列) は トライ木を実装するためのアルゴリズムの 1 つで、他の実装よりも高速に TRIE から文字列を検索できるらしい。ChaSen や MeCab で、形態素解析を行うために必要な Common-Prefix Search (共通接頭辞探索) を行うために使われている。これを理解のために Ruby で実装してみた。
基本的な動作確認
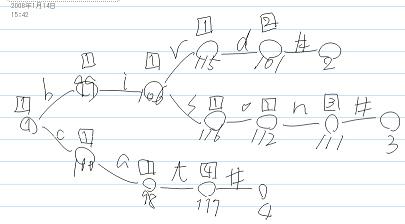
ここに書いてある bird, bison, cat の 3 単語で構築した Double-Array の例。
コード:
require 'trie/double_array' da = Trie::DoubleArray.new da.build(%w|bird bison cat|) 0.upto(da.base.length) do |i| next unless da.base[i] puts "node[#{i}]\tbase:#{da.base[i]}\tcheck:#{da.check[i]}" end
出力結果:
node[1] base:1 check:0 node[36] base:0 check:101 node[37] base:-1 check:111 node[38] base:-2 check:117 node[98] base:1 check:100 node[99] base:1 check:1 node[100] base:1 check:1 node[101] base:1 check:115 node[106] base:1 check:99 node[111] base:2 check:112 node[112] base:1 check:116 node[115] base:1 check:106 node[116] base:1 check:106 node[117] base:3 check:98
「文字コードとして ASCII を利用した場合」の図と照合してもだいたい合っている (末端ノードの base の値が異なるのは Darts に倣って元単語配列のインデクス番号をマイナスの値にしたものを格納しているため)。
Common-Prefix Search
小さな辞書を作って Common-Prefix Search を試してみる。
コード:
require 'trie/double_array' # 適当に作った CSV の辞書 (「表層,意味」の形式) dic = <<EOD あめ,雨(名詞) あめりか,アメリカ(名詞) か,か(助詞、疑問) か,蚊(名詞) かに,蟹(名詞) さ,差(名詞) じ,じ(助詞、意志打ち消し) じ,字(名詞) そで,袖(名詞) で,で(接続詞) でも,デモ(名詞) に,二(数詞) に,に(接続詞) ぬらさ,濡らさ(動詞、未然形) ふ,麩(名詞) ふる,降る(動詞、終止形) ふる,降る(動詞、連体形) め,目(名詞) め,芽(名詞) も,も(接続詞) り,利(名詞) りか,理科(名詞) EOD # 単語の表層がユニークなものを配列としてまとめる words, features = [], [] prev, tmp = '', [] dic.each_with_index do |line, i| word, feature = line.chomp.split(',') if i == 0 || word == prev tmp << feature else words << prev features << tmp tmp = [feature] end prev = word end words << prev features << tmp # Double-Array の構築 da = Trie::DoubleArray.new da.build(words) # Common-Prefix Search key = 'ふるあめりかにそでもぬらさじ' while key != '' res = da.common_prefix_search(key) puts "- #{key}" if res && res.size > 0 res.each do |i, len| w, f = words[i][0,len], features[i] puts " - #{w} [#{f.join('/')}]" end else puts " - [no match]" end key = key.split(//u)[1..-1].join end
出力結果:
- ふるあめりかにそでもぬらさじ - ふ [麩(名詞)] - ふる [降る(動詞、終止形)/降る(動詞、連体形)] - るあめりかにそでもぬらさじ - [no match] - あめりかにそでもぬらさじ - あめ [雨(名詞)] - あめりか [アメリカ(名詞)] - めりかにそでもぬらさじ - め [目(名詞)/芽(名詞)] - りかにそでもぬらさじ - り [利(名詞)] - りか [理科(名詞)] - かにそでもぬらさじ - か [か(助詞、疑問)/蚊(名詞)] - かに [蟹(名詞)] - にそでもぬらさじ - に [二(数詞)/に(接続詞)] - そでもぬらさじ - そで [袖(名詞)] - でもぬらさじ - で [で(接続詞)] - でも [デモ(名詞)] - もぬらさじ - も [も(接続詞)] - ぬらさじ - ぬらさ [濡らさ(動詞、未然形)] - らさじ - [no match] - さじ - さ [差(名詞)] - じ - じ [じ(助詞、意志打ち消し)/字(名詞)]
うまく動いているっぽい。
実装の特徴
TODO
{kind=link}
後記
アルゴリズムとか計算機科学の素養がなくて Double-Array 自体を理解するのにやたら時間がかかった。ちゃんとしたもの作れているか自信ないので、ソースや文章になんか間違ってるところあったら教えてもらえると嬉しいです。